介绍
Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。
1 | import tensorflow as tf |
1. 导入数据集:
1 | datasets = pd.read_csv('./input/Iris.csv') |
| Id | SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | Species | |
|---|---|---|---|---|---|---|
| 0 | 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| ... | ... | ... | ... | ... | ... | ... |
| 145 | 146 | 6.7 | 3.0 | 5.2 | 2.3 | Iris-virginica |
| 146 | 147 | 6.3 | 2.5 | 5.0 | 1.9 | Iris-virginica |
| 147 | 148 | 6.5 | 3.0 | 5.2 | 2.0 | Iris-virginica |
| 148 | 149 | 6.2 | 3.4 | 5.4 | 2.3 | Iris-virginica |
| 149 | 150 | 5.9 | 3.0 | 5.1 | 1.8 | Iris-virginica |
150 rows × 6 columns
2. 准备数据:X
1 | X = datasets[['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm',]] |
| SepalLengthCm | SepalWidthCm | PetalLengthCm | PetalWidthCm | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
| ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 |
150 rows × 4 columns
3. 准备数据:y
1 | #step1编码 |
1 | del datasets['Species'] |
1 | y=datasets.iloc[:,-3:] |
| Iris-setosa | Iris-versicolor | Iris-virginica | |
|---|---|---|---|
| 0 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 |
| 2 | 1 | 0 | 0 |
| 3 | 1 | 0 | 0 |
| 4 | 1 | 0 | 0 |
| ... | ... | ... | ... |
| 145 | 0 | 0 | 1 |
| 146 | 0 | 0 | 1 |
| 147 | 0 | 0 | 1 |
| 148 | 0 | 0 | 1 |
| 149 | 0 | 0 | 1 |
150 rows × 3 columns
4. 划分测试集训练集
1 | train_X, test_X, train_y, test_y = train_test_split(X, y, test_size = 0.2, random_state = 42) |
(120, 4) (120, 3) (30, 4) (30, 3)
5. 搭建模型
1 | model = keras.Sequential() |
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 3) 15
=================================================================
Total params: 15
Trainable params: 15
Non-trainable params: 0
_________________________________________________________________
6. 编译模型
1 | model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['acc']) |
7. 训练模型
1 | history=model.fit(train_X,train_y,epochs=500,validation_data=(test_X,test_y)) |
8. 评估模型
1 | loss,acc = model.evaluate(train_X,train_y) |
4/4 [==============================] - 0s 1ms/step - loss: 0.4869 - acc: 0.9333
1 | loss,acc = model.evaluate(test_X,test_y) |
1/1 [==============================] - 0s 25ms/step - loss: 0.4598 - acc: 0.9667
1 | plt.plot(history.epoch,history.history.get('acc'),label = "acc") |
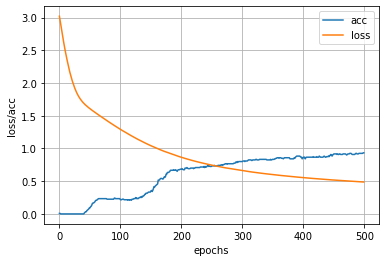
9. 预测模型
1 | prediction = model.predict(test_X) |
1 | #查看第一个 |
1
10. 存储模型
10.1 使用 h5py生成模型
1 | import h5py |
10.2 使用模型
1 | from keras.models import load_model |
10.3 运用新模型预测
1 | pred=model.predict(np.array([[5.5, 2.4, 3.7, 1. ]])) |
1
下面的模型生成有报错信息,不知道什么原因?
11.1 使用 pickle存储模型
1 | import joblib |
INFO:tensorflow:Assets written to: ram://806e146a-aef3-4ddb-8f95-0e484b2bda19/assets
['test.pkl']
1 | m=joblib.load('test.pkl') |
1 | import pickle |
11.2 使用 pickle存储模型并利用gzip压缩
1 | import pickle |
12. 载入模型
#注意模型预测输入必须为numpy形态,并且为二维矩阵格式
12 载入pickle模型
1 | #讀取Model |
1 |
赏
使用支付宝打赏
使用微信打赏
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏
扫描二维码,分享此文章